大家都知道一个游戏里面会有大量的图片,每一个图片渲染是须要时间的,以下分析两个类来加快渲染速度,加快游戏执行速度
一、SpriteBatchNode
1、先说下渲染批次:这是游戏引擎中一个比較重要的优化指标,指的是一次渲染凋用。
2、SpriteBatchNode就是cocos2d-x为了减少渲染批次而建立的一个专门管理精灵的类。
有人会问。怎么高速知道究竟渲染了多少次了。告诉你吧,游戏左下角有三行数据:
GL verts 表示给显卡绘制的顶点数
GL calls 表示代表每一帧中OpenGL指令的调用次数
FPS 这个是帧率不多说
主要看第二个“GL calls”代表每一帧中OpenGL指令的调用次数,这个数字越小,程序的绘制性能就越好。
首先我们使用sprite创建100个精灵,看看这个值是多少
code:
for(int i = 0; i < 100; ++ i)
{
char name[15];
memset(name, 0, sizeof(name));
sprintf(name, "%d.png", i % 10);
auto sp = Sprite::create(name);
sp->setPosition(Point(i*5,i*5));
node->addChild(sp);
}
this->addChild(node);
这个循环创建了100个精灵,显示出来,看效果
 看左下角红色圈圈,有101次绘制,当中100个元素每一个元素绘制一次,多出来的一次是绘制这个左下角信息自己。
看左下角红色圈圈,有101次绘制,当中100个元素每一个元素绘制一次,多出来的一次是绘制这个左下角信息自己。
在来看看使用SpriteBatchNode
code:
auto spBatchNode = SpriteBatchNode::create("0.png");
spBatchNode->setPosition(Point::ZERO);
this->addChild(spBatchNode);
for(int i = 0; i < 100; ++ i)
{
count++;
//float x = CCRANDOM_0_1() * visibleSize.width;
//float y = CCRANDOM_0_1() * visibleSize.height;
//log("x=%lf, y=%lf",x, y);
char name[15];
memset(name, 0, sizeof(name));
sprintf(name, "%d.png", i % 10);
auto sp = Sprite::createWithTexture(spBatchNode->getTexture());
sp->setPosition(Point(i*5,i*5));
spBatchNode->addChild(sp);
}看效果图
 看到没,立刻减到2了。这快了太多了。
看到没,立刻减到2了。这快了太多了。
二、SpriteFrameCache
首先我们使用合图软件,将这10张图合成一张大图和一个plist文件。
code:
SpriteFrameCache::getInstance()->addSpriteFramesWithFile("test.plist","test.png");
Node* node = Node::create();
char name[32];
for(int i = 0;i<100;++i)
{
char name[15];
memset(name, 0, sizeof(name));
//auto sprite = Sprite::create(name);
auto sprite = Sprite::createWithSpriteFrameName(name);
sprite->setPosition(Point(i*5,i*5));
node->addChild(sprite, 0);
}
this->addChild(node);
这段代码中,我们调用addSpriteFramesWithFile函数,将大图加载到内存中,创建对象时,调用createWithSpriteFrameName从缓存纹理中加载图片。

我们能够很明显的看到。优化后的程序“GL calls”依旧变成了2次。
另一种优化,就是当精灵超出屏幕后就剔除掉,这样也能降低OpenGL指令。
三、绘制剔除
相对于上一种优化,这个要更easy理解。
code:
Node* node = Node::create();
for(int i = 0;i<100;++i)
{
char name[15];
memset(name, 0, sizeof(name));
sprintf(name, "%d.png",i%10);
auto sprite = Sprite::create(name);
//auto sprite = Sprite::createWithSpriteFrameName(name);
sprite->setPosition(Point(i*5,i*5));
node->addChild(sprite, 0);
}
this->addChild(node);
auto listener = EventListenerTouchOneByOne::create();
listener->onTouchBegan = [=](Touch *pTouch, Event *pEvent)
{
return true;
};
listener->onTouchMoved = [=](Touch *pTouch, Event *pEvent)
{
node->setPosition(node->getPosition()+pTouch->getDelta());
};
Director::getInstance()->getEventDispatcher()->
addEventListenerWithSceneGraphPriority(listener, this);
return true;}
效果图例如以下:
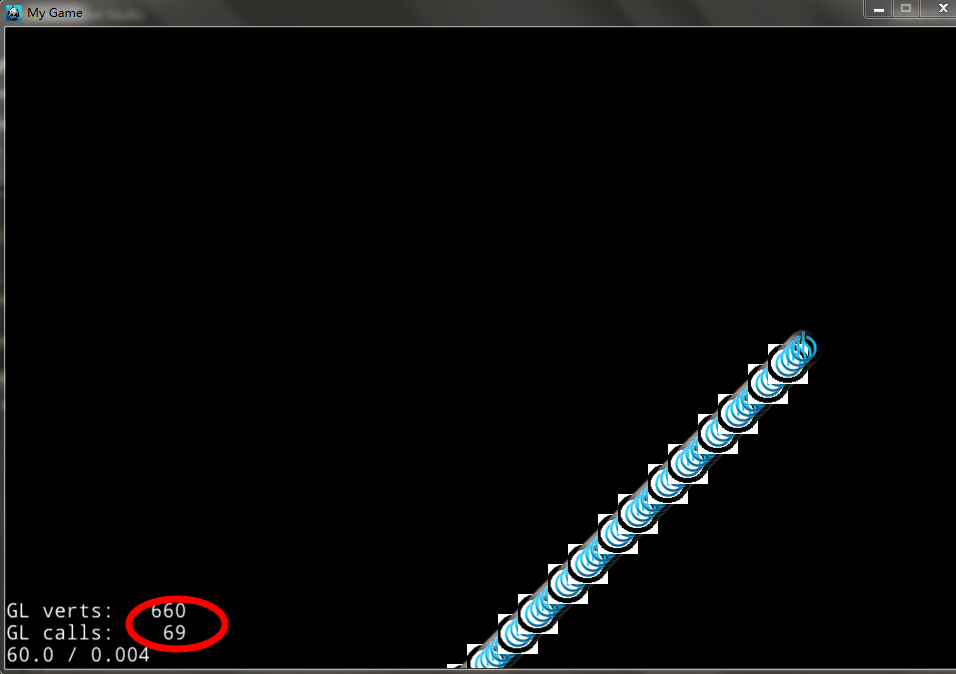
我们发现GL calls也变小了,这也是一种不错的方法
四、总结 大体。这两个优化,可以说,该方案的性能有了很大的提高。同时在发展过程,也使程序猿没有太多纠缠在渲染效率优化。
一、SpriteBatchNode
1、先说下渲染批次:这是游戏引擎中一个比較重要的优化指标,指的是一次渲染凋用。
也就是说,渲染的次数越少,游戏的执行效率越高。
2、SpriteBatchNode就是cocos2d-x为了减少渲染批次而建立的一个专门管理精灵的类。
有人会问。怎么高速知道究竟渲染了多少次了。告诉你吧,游戏左下角有三行数据:
GL verts 表示给显卡绘制的顶点数
GL calls 表示代表每一帧中OpenGL指令的调用次数
FPS 这个是帧率不多说
主要看第二个“GL calls”代表每一帧中OpenGL指令的调用次数,这个数字越小,程序的绘制性能就越好。
我们有没有法子让他小点了,答案当然是yes
首先我们使用sprite创建100个精灵,看看这个值是多少
code:
for(int i = 0; i < 100; ++ i)
{
char name[15];
memset(name, 0, sizeof(name));
sprintf(name, "%d.png", i % 10);
auto sp = Sprite::create(name);
sp->setPosition(Point(i*5,i*5));
node->addChild(sp);
}
this->addChild(node);
这个循环创建了100个精灵,显示出来,看效果
看左下角红色圈圈,有101次绘制,当中100个元素每一个元素绘制一次,多出来的一次是绘制这个左下角信息自己。 在来看看使用SpriteBatchNode
code:
auto spBatchNode = SpriteBatchNode::create("0.png");
spBatchNode->setPosition(Point::ZERO);
this->addChild(spBatchNode);
for(int i = 0; i < 100; ++ i)
{
count++;
//float x = CCRANDOM_0_1() * visibleSize.width;
//float y = CCRANDOM_0_1() * visibleSize.height;
//log("x=%lf, y=%lf",x, y);
char name[15];
memset(name, 0, sizeof(name));
sprintf(name, "%d.png", i % 10);
auto sp = Sprite::createWithTexture(spBatchNode->getTexture());
sp->setPosition(Point(i*5,i*5));
spBatchNode->addChild(sp);
}看效果图
看到没,立刻减到2了。这快了太多了。 这是一个提速,在来看看SpriteFrameCache
二、SpriteFrameCache
首先我们使用合图软件,将这10张图合成一张大图和一个plist文件。
在使用CocoStudio导出时。选择“使用大图”就可以将小图合成一张大图。当然我们也能够选择TexturePacker这样的专业的合图软件,合成的图片分为“test.png”和“test.plist”两部分,然后使用SpriteFrameCache。
code:
SpriteFrameCache::getInstance()->addSpriteFramesWithFile("test.plist","test.png");
Node* node = Node::create();
char name[32];
for(int i = 0;i<100;++i)
{
char name[15];
memset(name, 0, sizeof(name));
//auto sprite = Sprite::create(name);
auto sprite = Sprite::createWithSpriteFrameName(name);
sprite->setPosition(Point(i*5,i*5));
node->addChild(sprite, 0);
}
this->addChild(node);
这段代码中,我们调用addSpriteFramesWithFile函数,将大图加载到内存中,创建对象时,调用createWithSpriteFrameName从缓存纹理中加载图片。
如此做我们全部的绘制调用都能够合并到一次OpenGL指令中,这些绘制指令的计算与合并都由Cocos2d-x引擎完毕。编译执行例如以下图所看到的:
我们能够很明显的看到。优化后的程序“GL calls”依旧变成了2次。
另一种优化,就是当精灵超出屏幕后就剔除掉,这样也能降低OpenGL指令。
三、绘制剔除
相对于上一种优化,这个要更easy理解。
它是指当一个元素移动到屏幕之外,就不进行绘制。
code:
Node* node = Node::create();
for(int i = 0;i<100;++i)
{
char name[15];
memset(name, 0, sizeof(name));
sprintf(name, "%d.png",i%10);
auto sprite = Sprite::create(name);
//auto sprite = Sprite::createWithSpriteFrameName(name);
sprite->setPosition(Point(i*5,i*5));
node->addChild(sprite, 0);
}
this->addChild(node);
auto listener = EventListenerTouchOneByOne::create();
listener->onTouchBegan = [=](Touch *pTouch, Event *pEvent)
{
return true;
};
listener->onTouchMoved = [=](Touch *pTouch, Event *pEvent)
{
node->setPosition(node->getPosition()+pTouch->getDelta());
};
Director::getInstance()->getEventDispatcher()->
addEventListenerWithSceneGraphPriority(listener, this);
return true;}
效果图例如以下:
我们发现GL calls也变小了,这也是一种不错的方法
四、总结 大体。这两个优化,可以说,该方案的性能有了很大的提高。同时在发展过程,也使程序猿没有太多纠缠在渲染效率优化。